
即时编译助力人大金仓KES分析能力飞跃
随着数字化技术对各行各业的不断渗透,人大金仓在金融、能源、电信等行业逐步进入深水区,面临越来越多的核心类系统改造升级,这些系统不仅需要满足在线交易系统运行的高实时性要求,还需要保证高效分析能力以帮助客户进行业务决策。
数据库中SQL表达式及PLSQL代码实现的都是通用逻辑,这就导致在语句执行过程中可能形成大量不必要的逻辑跳转和代码分支遍历,进而成倍甚至成指数级增加底层指令的执行,造成CPU过高压力。尤其在较为复杂分析类计算场景中,这种性能损耗尤其严重。
为了解决这种无效性能损耗,KES使用动态编译(Just-in-timecompilation,JIT)技术,将代码扁平化执行。简单说就是通过直接调用对应的函数,并且在已知输入情况下精简代码逻辑分支的方式,在复杂计算的分析场景下显著降低CPU单位负载压力,有效提高数据库整体性能。
在解释JIT之前,我们先来了解下什么是编译器:它是将高级语言源代码翻译成机器语言(或翻译成比原始程序低级代码)的程序。

在以前,程序通常有两种编译运行方式-静态编译与动态直译,现如今又出现了即时编译方式。
提前(Ahead-of-Time:AOT)编译-即静态编译:在运行应用程序之前预编译应用程序的编译。

2、解释器(interpreter)-动态直译:执行以编程语言编写的源代码或中间表达式并按顺序解释它们的程序。

即时(JIT)编译融合了前二种编译方式,一句一句编译源代码执行,同时将编译过的代码缓存起来以降低性能损耗。相对于静态编译,即时编译的代码可以处理延迟绑定并增强安全性。简单的说,JIT是一种提高程序运行效率的方法。

KES把对应的JIT的提供者封装成一个依赖库,从而避免了JIT对内核代码的侵入性。用户可以按需开启或关闭JIT功能;通过进一步的抽象,KES还提供支持后期扩展不同JIT的解决方案。其JIT实现过程概述如下:
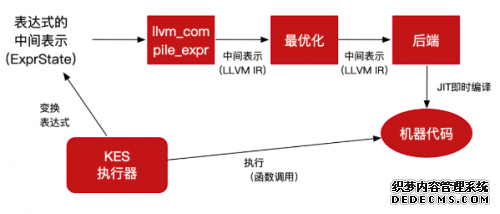
针对WHERE条件判断、聚合运算等场景实时将表达式的路径编译为具体代码执行,在此过程中大量的不必要的调用和分支跳转会被优化掉。
数据库执行器通过存取层装载数据,针对特定的表结构,可以定制读取和解析元组的代码。如在解析元组的流程中,根据表结构动态生成的代码,无需做数据类型的重复判断,只按照顺序解析数据;以及在获取部分列时实现直接根据对应偏移量提取的数据,跳过不需要提取的列,从而降低计算及I/O开销。随着处理的数据量的增加,节省的计算及I/O量将是惊人的。
LLVM中实现了对产生的中间表示代码(IR)的优化,这一定程度上也会提升数据库查询的执行速度。从每一行数据的处理优化提升到整条SQL的处理流程优化:从传统的相对低效的流水线执行方式调整为循环批量处理方式,从而充分利用CPU缓存,尽量避免去相对慢得多的内存中存取数据;再结合CPU向量计算相关指令集,进一步提高性能。
JIT会提升CPU密集型查询的性能,而对于短查询的优化有限,KES默认开启动态编译(JIT),运行时会比较查询的评估代价与JIT代价阀值的大小,判断是否执行JIT编译。用户也可以根据业务需要主动设置JIT参数关闭动态编译。
下面通过一个客户业务分析场景的脱敏简化版对比说明JIT对SQL执行性能的提升:
JIT可以帮助KES数据库优化SQL执行逻辑,加快复杂SQL的查询速度,从而提升KES整体性能。在TPC-H等数据库测试中,KES的JIT编译表达式执行速度快了不止20%;在JIT模式下,创建索引的速度普遍可以提高5%-19%。
作为国内成立最早、底蕴最深的数据库国家队,人大金仓始终以用户为中心,致力于提供卓越的数据库产品与服务。金仓人在广泛关注及学习前沿技术的同时,坚持自主创新,不断落地新理论,融合新技术,以满足日趋多元且极致的新需求,提升产品核心竞争力,持续为千行百业数字化转型升级赋能。
相关文章


